Deep Agents 可以创建子智能体来委托工作。您可以在 subagents 参数中指定自定义子智能体。子智能体对于上下文隔离(保持主智能体的上下文清洁)和提供专门化指令非常有用。
本页面介绍同步子智能体,即监督者阻塞直到子智能体完成。对于长时间运行的任务、并行工作流或需要中途控制和取消的情况,请参阅异步子智能体。
为什么使用子智能体?
子智能体解决了上下文膨胀问题。当智能体使用输出较大的工具(网络搜索、文件读取、数据库查询)时,上下文窗口会迅速被中间结果填满。子智能体隔离这些详细工作——主智能体只接收最终结果,而不是产生该结果的数十次工具调用。
何时使用子智能体:
- ✅ 会使主智能体上下文混乱的多步骤任务
- ✅ 需要自定义指令或工具的专门领域
- ✅ 需要不同模型能力的任务
- ✅ 当您希望主智能体专注于高层协调时
何时不使用子智能体:
- ❌ 简单的单步任务
- ❌ 需要维护中间上下文时
- ❌ 开销大于收益时
subagents 应该是字典列表或 CompiledSubAgent 对象。有两种类型:
SubAgent(基于字典)
对于大多数用例,将子智能体定义为与 SubAgent 规范匹配的字典,具有以下字段:
| 字段 | 类型 | 描述 |
|---|
name | str | 必需。子智能体的唯一标识符。主智能体在调用 task() 工具时使用此名称。子智能体名称成为 AIMessage 和流式传输的元数据,有助于区分不同智能体。 |
description | str | 必需。子智能体的用途描述。请具体且以动作为导向。主智能体使用此描述来决定何时委托。 |
system_prompt | str | 必需。子智能体的指令。自定义子智能体必须定义自己的指令。包括工具使用指导和输出格式要求。
不从主智能体继承。 |
tools | list[Callable] | 必需。子智能体可以使用的工具。自定义子智能体指定自己的工具。保持最小化,只包含所需的工具。
不从主智能体继承。 |
model | str | BaseChatModel | 可选。覆盖主智能体的模型。省略则使用主智能体的模型。
默认从主智能体继承。可以传入模型标识符字符串如 'openai:gpt-5'(使用 'provider:model' 格式)或 LangChain 聊天模型对象(init_chat_model("gpt-5") 或 ChatOpenAI(model="gpt-5"))。 |
middleware | list[Middleware] | 可选。用于自定义行为、日志记录或速率限制的附加中间件。
不从主智能体继承。 |
interrupt_on | dict[str, bool] | 可选。为特定工具配置人工介入。子智能体值覆盖主智能体。需要检查点。
默认从主智能体继承。子智能体值覆盖默认值。 |
skills | list[str] | 可选。技能源路径。指定后,子智能体将从这些目录加载技能(例如 ["/skills/research/", "/skills/web-search/"])。这允许子智能体拥有与主智能体不同的技能集。
不从主智能体继承。只有通用子智能体继承主智能体的技能。当子智能体有技能时,它运行自己独立的 SkillsMiddleware 实例。技能状态完全隔离——子智能体加载的技能对父级不可见,反之亦然。 |
permissions | list[FilesystemPermission] | 可选。子智能体的文件系统权限规则。设置后,完全替换父智能体的权限。
默认从主智能体继承。 |
**CLI 用户:**您还可以将子智能体定义为磁盘上的 AGENTS.md 文件,而不是在代码中定义。name、description 和 model 字段映射到 YAML frontmatter,markdown 正文成为 system_prompt。有关文件格式,请参阅自定义子智能体。 CompiledSubAgent
对于复杂的工作流,使用预构建的 LangGraph 图作为 CompiledSubAgent:
| 字段 | 类型 | 描述 |
|---|
name | str | 必需。子智能体的唯一标识符。子智能体名称成为 AIMessage 和流式传输的元数据,有助于区分不同智能体。 |
description | str | 必需。此子智能体的用途。 |
runnable | Runnable | 必需。编译后的 LangGraph 图(必须先调用 .compile())。 |
使用 SubAgent
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
research_subagent = {
"name": "research-agent",
"description": "Used to research more in depth questions",
"system_prompt": "You are a great researcher",
"tools": [internet_search],
"model": "openai:gpt-5.2", # Optional override, defaults to main agent model
}
subagents = [research_subagent]
agent = create_deep_agent(
model="claude-sonnet-4-6",
subagents=subagents
)
使用 CompiledSubAgent
对于更复杂的用例,您可以使用 CompiledSubAgent 为自定义子智能体提供更强大的功能。
您可以使用 LangChain 的 create_agent 创建自定义子智能体,或使用图 API制作自定义 LangGraph 图。
如果您正在创建自定义 LangGraph 图,请确保该图有一个名为 "messages" 的状态键:
from deepagents import create_deep_agent, CompiledSubAgent
from langchain.agents import create_agent
# 创建一个自定义智能体图
custom_graph = create_agent(
model=your_model,
tools=specialized_tools,
prompt="您是一个专门用于数据分析的智能体..."
)
# 将其用作自定义子智能体
custom_subagent = CompiledSubAgent(
name="data-analyzer",
description="用于复杂数据分析任务的专门智能体",
runnable=custom_graph
)
subagents = [custom_subagent]
agent = create_deep_agent(
model="claude-sonnet-4-6",
tools=[internet_search],
system_prompt=research_instructions,
subagents=subagents
)
流式处理
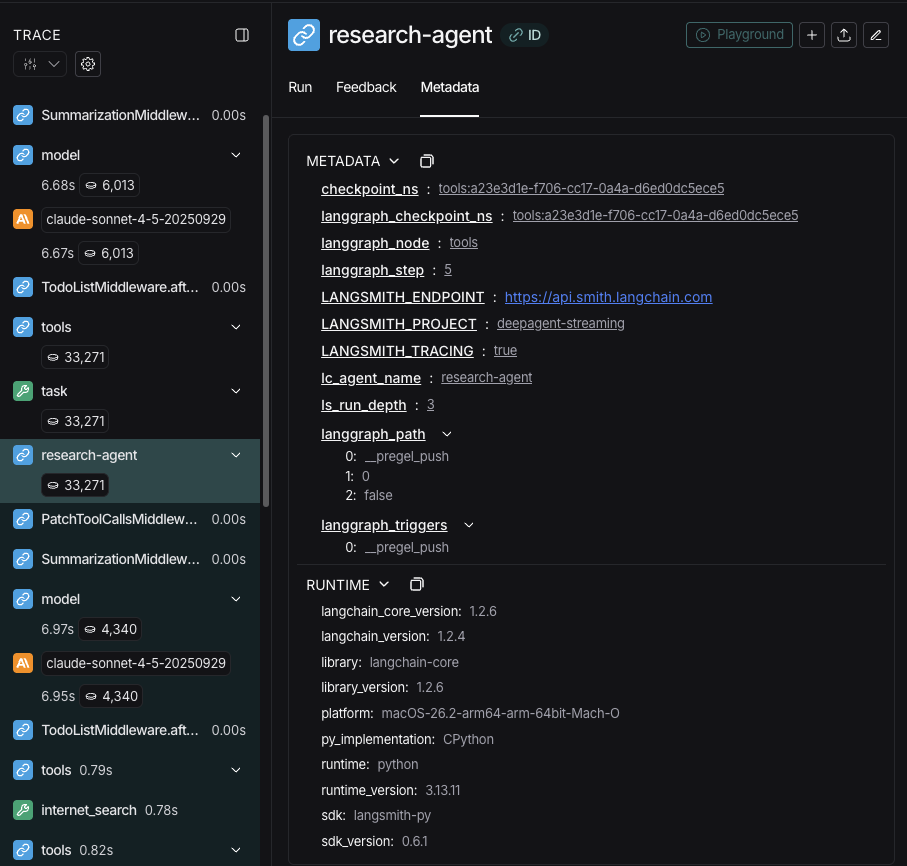
当流式传输追踪信息时,智能体名称在元数据中作为 lc_agent_name 可用。
在查看追踪信息时,您可以使用此元数据来区分数据来自哪个智能体。
以下示例创建一个名为 main-agent 的 Deep Agent 和一个名为 research-agent 的子智能体:
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""执行网络搜索"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
research_subagent = {
"name": "research-agent",
"description": "用于更深入地研究问题",
"system_prompt": "您是一位优秀的研究员",
"tools": [internet_search],
"model": "claude-sonnet-4-6", # 可选覆盖,默认为主智能体模型
}
subagents = [research_subagent]
agent = create_deep_agent(
model="claude-sonnet-4-6",
subagents=subagents,
name="main-agent"
)
"research-agent" 的子智能体将在任何相关的智能体运行元数据中具有 {'lc_agent_name': 'research-agent'}:
结构化输出
所有子智能体都支持结构化输出,您可以使用它来验证子智能体的输出。
您可以通过将所需的结构化输出模式作为 response_format 参数传递给 create_agent() 调用来设置它。
当模型生成结构化数据时,它会被捕获和验证。
结构化对象本身不会返回给父智能体。
当将结构化输出与子智能体一起使用时,将结构化数据包含在 ToolMessage 中。
有关更多信息,请参阅响应格式。
通用子智能体
除了用户定义的子智能体外,Deep Agents 始终可以访问一个 通用 子智能体。此子智能体:
- 具有与主智能体相同的系统提示
- 有权访问所有相同的工具
- 使用相同的模型(除非被覆盖)
- 从主智能体继承技能(当配置了技能时)
覆盖通用子智能体
在您的 subagents 列表中包含一个名为 name="general-purpose" 的子智能体来替换默认的。使用此功能为通用子智能体配置不同的模型、工具或系统提示:
from deepagents import create_deep_agent
# 主智能体使用 Claude;通用子智能体使用 GPT
agent = create_deep_agent(
model="claude-sonnet-4-6",
tools=[internet_search],
subagents=[
{
"name": "general-purpose",
"description": "用于研究和多步骤任务的通用智能体",
"system_prompt": "您是一个通用助手。",
"tools": [internet_search],
"model": "openai:gpt-4o", # 委托任务使用不同的模型
},
],
)
何时使用
通用子智能体非常适合无需专门行为的上下文隔离。主智能体可以将复杂的多步骤任务委托给此子智能体,并获得简洁的结果,而不会因中间工具调用而膨胀。
示例
主智能体不进行 10 次网络搜索并用结果填充其上下文,而是委托给通用子智能体:task(name="general-purpose", task="研究量子计算趋势")。子智能体在内部执行所有搜索,只返回摘要。
技能继承
使用 create_deep_agent 配置技能时:
- 通用子智能体:自动从主智能体继承技能
- 自定义子智能体:默认不继承技能——使用
skills 参数为它们提供自己的技能
只有使用技能配置的子智能体才会获得 SkillsMiddleware 实例——没有 skills 参数的自定义子智能体不会。当存在时,技能状态在两个方向上完全隔离:父级的技能对子级不可见,子级的技能也不会传播回父级。
from deepagents import create_deep_agent
# 具有自己技能的研究子智能体
research_subagent = {
"name": "researcher",
"description": "具有专门技能的研究助手",
"system_prompt": "您是一位研究员。",
"tools": [web_search],
"skills": ["/skills/research/", "/skills/web-search/"], # 子智能体特定的技能
}
agent = create_deep_agent(
model="claude-sonnet-4-6",
skills=["/skills/main/"], # 主智能体和通用子智能体获得这些
subagents=[research_subagent], # 只获得 /skills/research/ 和 /skills/web-search/
)
最佳实践
编写清晰的描述
主智能体使用描述来决定调用哪个子智能体。要具体:
✅ 好: "分析财务数据并生成带置信度分数的投资见解"
❌ 差: "做一些财务相关的事情"
保持系统提示详细
包括有关如何使用工具和格式化输出的具体指导:
research_subagent = {
"name": "research-agent",
"description": "使用网络搜索进行深入研究并综合发现",
"system_prompt": """您是一位细致的研究员。您的任务是:
1. 将研究问题分解为可搜索的查询
2. 使用 internet_search 查找相关信息
3. 将发现综合成全面但简洁的摘要
4. 在提出声明时引用来源
输出格式:
- 摘要(2-3 段)
- 主要发现(要点列表)
- 来源(带 URL)
保持响应在 500 字以内以保持上下文清洁。""",
"tools": [internet_search],
}
最小化工具集
只给子智能体它们需要的工具。这可以提高专注度和安全性:
# ✅ 好:集中的工具集
email_agent = {
"name": "email-sender",
"tools": [send_email, validate_email], # 只包含邮件相关
}
# ❌ 差:工具太多
email_agent = {
"name": "email-sender",
"tools": [send_email, web_search, database_query, file_upload], # 不专注
}
根据任务选择模型
不同的模型擅长不同的任务:
subagents = [
{
"name": "contract-reviewer",
"description": "审查法律文档和合同",
"system_prompt": "您是一位专业的法律审查员...",
"tools": [read_document, analyze_contract],
"model": "claude-sonnet-4-6", # 长文档的大上下文
},
{
"name": "financial-analyst",
"description": "分析财务数据和市场趋势",
"system_prompt": "您是一位专业的财务分析师...",
"tools": [get_stock_price, analyze_fundamentals],
"model": "openai:gpt-5", # 更适合数值分析
},
]
返回简洁的结果
指示子智能体返回摘要,而不是原始数据:
data_analyst = {
"system_prompt": """分析数据并返回:
1. 主要见解(3-5 个要点)
2. 整体置信度分数
3. 建议的后续行动
不要包括:
- 原始数据
- 中间计算
- 详细的工具输出
保持响应在 300 字以内。"""
}
常见模式
多个专门子智能体
为不同领域创建专门子智能体:
from deepagents import create_deep_agent
subagents = [
{
"name": "data-collector",
"description": "从各种来源收集原始数据",
"system_prompt": "收集关于该主题的全面数据",
"tools": [web_search, api_call, database_query],
},
{
"name": "data-analyzer",
"description": "分析收集的数据以获取见解",
"system_prompt": "分析数据并提取关键见解",
"tools": [statistical_analysis],
},
{
"name": "report-writer",
"description": "根据分析撰写精美的报告",
"system_prompt": "根据见解创建专业报告",
"tools": [format_document],
},
]
agent = create_deep_agent(
model="claude-sonnet-4-6",
system_prompt="您协调数据分析和平面报告。使用子智能体处理专门任务。",
subagents=subagents
)
- 主智能体创建高层计划
- 将数据收集委托给 data-collector
- 将结果传递给 data-analyzer
- 将见解发送给 report-writer
- 编译最终输出
每个子智能体使用专注于其任务的清洁上下文工作。
上下文管理
当您使用运行时上下文调用父智能体时,该上下文会自动传播到所有子智能体。每个子智能体运行接收与父 invoke / ainvoke 调用传递相同的运行时上下文。
这意味着在任何子智能体内运行的工具可以访问您传递给父级的相同上下文值:
from dataclasses import dataclass
from deepagents import create_deep_agent
from langchain.messages import HumanMessage
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
session_id: str
@tool
def get_user_data(query: str, runtime: ToolRuntime[Context]) -> str:
"""获取当前用户的数据。"""
user_id = runtime.context.user_id
return f"Data for user {user_id}: {query}"
research_subagent = {
"name": "researcher",
"description": "为当前用户进行研究",
"system_prompt": "您是一位研究助手。",
"tools": [get_user_data],
}
agent = create_deep_agent(
model="claude-sonnet-4-6",
subagents=[research_subagent],
context_schema=Context,
)
# 上下文自动流向 researcher 子智能体及其工具
result = await agent.invoke(
{"messages": [HumanMessage("查找我最近的活动")]},
context=Context(user_id="user-123", session_id="abc"),
)
每个子智能体的上下文
所有子智能体接收相同的父上下文。要传递特定于某个子智能体的配置,请使用命名空间键(用子智能体名称前缀键,例如 researcher:max_depth)在扁平 context 映射中,或者将这些设置建模为上下文类型的单独字段:
from dataclasses import dataclass
from langchain.messages import HumanMessage
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
researcher_max_depth: int | None = None
fact_checker_strict_mode: bool | None = None
result = await agent.invoke(
{"messages": [HumanMessage("研究这个并验证声明")]},
context=Context(
user_id="user-123",
researcher_max_depth=3,
fact_checker_strict_mode=True,
),
)
@tool
def verify_claim(claim: str, runtime: ToolRuntime[Context]) -> str:
"""验证事实声明。"""
strict_mode = runtime.context.fact_checker_strict_mode or False
if strict_mode:
return strict_verification(claim)
return basic_verification(claim)
识别哪个子智能体调用了工具
当同一工具在父级和多个子智能体之间共享时,您可以使用 lc_agent_name 元数据(与流式处理中使用相同的值)来确定哪个智能体发起了调用:
from langchain.tools import tool, ToolRuntime
@tool
def shared_lookup(query: str, runtime: ToolRuntime) -> str:
"""查找信息。"""
agent_name = runtime.config.get("metadata", {}).get("lc_agent_name")
if agent_name == "fact-checker":
return strict_lookup(query)
return general_lookup(query)
runtime.context 读取智能体特定设置,并在分支工具行为时从 runtime.config 元数据读取 lc_agent_name。
from langchain.tools import tool, ToolRuntime
@tool
def flexible_search(query: str, runtime: ToolRuntime[Context]) -> str:
"""使用智能体特定设置进行搜索。"""
agent_name = runtime.config.get("metadata", {}).get("lc_agent_name", "unknown")
ctx = runtime.context
if agent_name == "researcher":
max_results = ctx.researcher_max_depth or 5
else:
max_results = 5
include_raw = False
return perform_search(query, max_results=max_results, include_raw=include_raw)
故障排除
子智能体未被调用
如果您的主智能体未调用子智能体,请检查:
- 描述是否清晰且以动作为导向? 主智能体根据描述来决定是否委托。
- 工具是否包含在主智能体的工具列表中?
task 工具必须在主智能体的工具中。
- 模型是否支持工具调用? 确保您的模型支持工具调用。
子智能体返回空结果
如果子智能体返回空或不完整的结果:
- 检查系统提示是否包含足够的指令
- 验证工具是否正确传递给子智能体
- 确保子智能体模型能够处理请求
上下文未传播
如果子智能体无法访问父智能体的上下文:
- 确认
context_schema 在主智能体和子智能体中正确配置
- 对于共享工具,检查
lc_agent_name 元数据

