

概述
在本教程中,我们将使用 LangGraph 构建一个检索 Agent。 LangChain 提供了内置的 agent 实现,使用 LangGraph 原语实现。如果需要更深入的定制,可以直接在 LangGraph 中实现 Agent。本指南演示了检索 Agent 的示例实现。检索 Agent 在您希望 LLM 决定是否从向量存储中检索上下文或直接响应用户时非常有用。 在本教程结束时,我们将完成以下操作:- 获取并预处理将用于检索的文档。
- 为语义搜索索引这些文档,并创建 Agent 的检索器工具。
- 构建一个可以决定何时使用检索器工具的 Agentic RAG 系统。
概念
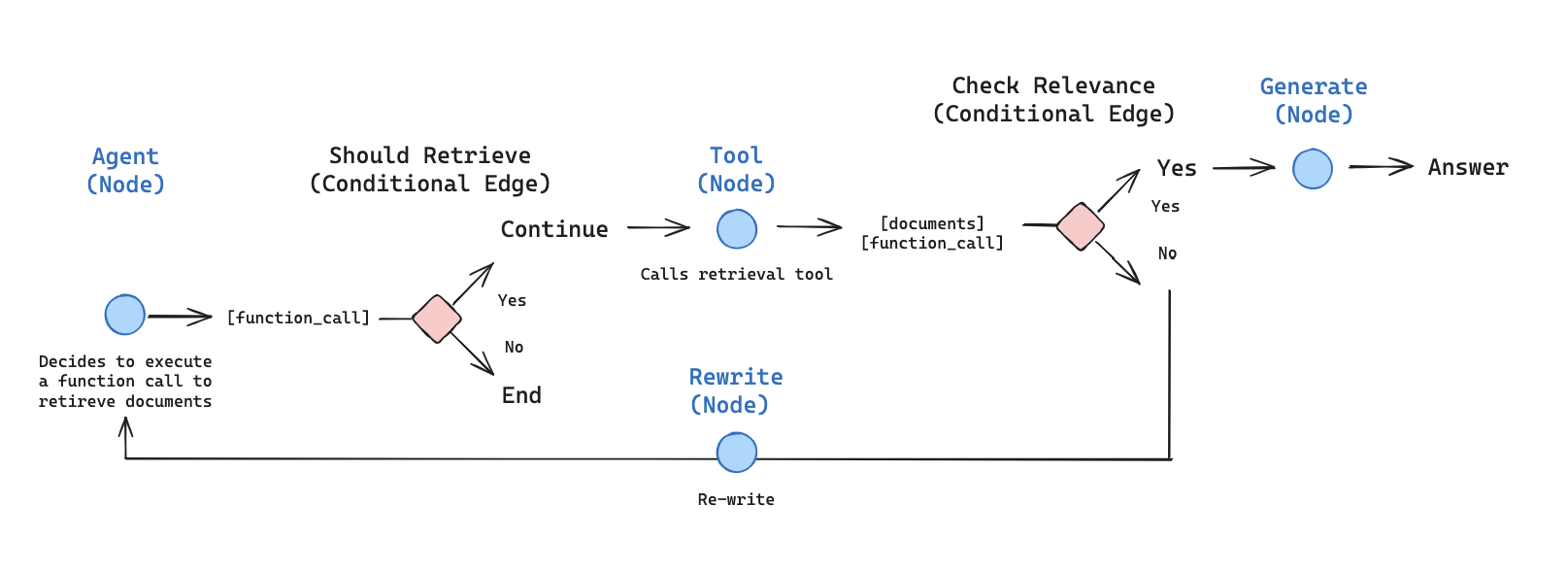
我们将涵盖以下概念:设置
让我们下载所需的包并设置我们的 API 密钥:1. 预处理文档
- 获取将在 RAG 系统中使用的文档。我们将使用 Lilian Weng 优秀博客中最新的三页。我们首先使用
WebBaseLoader工具获取页面的内容:
- 将获取的文档分割成更小的块,以便索引到向量存储中:
2. 创建检索器工具
现在我们有了分割好的文档,可以将它们索引到向量存储中,用于语义搜索。- 使用内存向量存储和 OpenAI 嵌入:
- 使用
@tool装饰器创建检索器工具:
- 测试工具:
3. 生成查询
现在我们将开始为我们的 Agentic RAG 图构建组件(节点和边)。 请注意,组件将在MessagesState——包含带有聊天消息列表的 messages 键的图状态——上操作。
- 构建一个
generate_query_or_respond节点。它将调用 LLM 根据当前图状态(消息列表)生成响应。给定输入消息,它将决定使用检索器工具进行检索,或直接响应用户。请注意,我们通过.bind_tools授予聊天模型对我们之前创建的retriever_tool的访问权限:
- 在随机输入上尝试:
- 问一个需要语义搜索的问题:
4. 文档评分
- 添加一个条件边——
grade_documents——来确定检索到的文档是否与问题相关。我们将使用带有结构化输出模式GradeDocuments的模型进行文档评分。grade_documents函数将根据评分决定返回要前往的节点名称(generate_answer或rewrite_question):
- 使用工具响应中的不相关文档运行此函数:
- 确认相关文档被分类为相关:
5. Rewrite question
- 构建
rewrite_question节点。检索器工具可能返回不相关的文档,这表明需要改进原始用户问题。为此,我们将调用rewrite_question节点:
- 尝试一下:
6. Generate an answer
- 构建
generate_answer节点:如果我们通过了评分器检查,我们可以根据原始问题和检索到的上下文生成最终答案:
- 尝试一下:
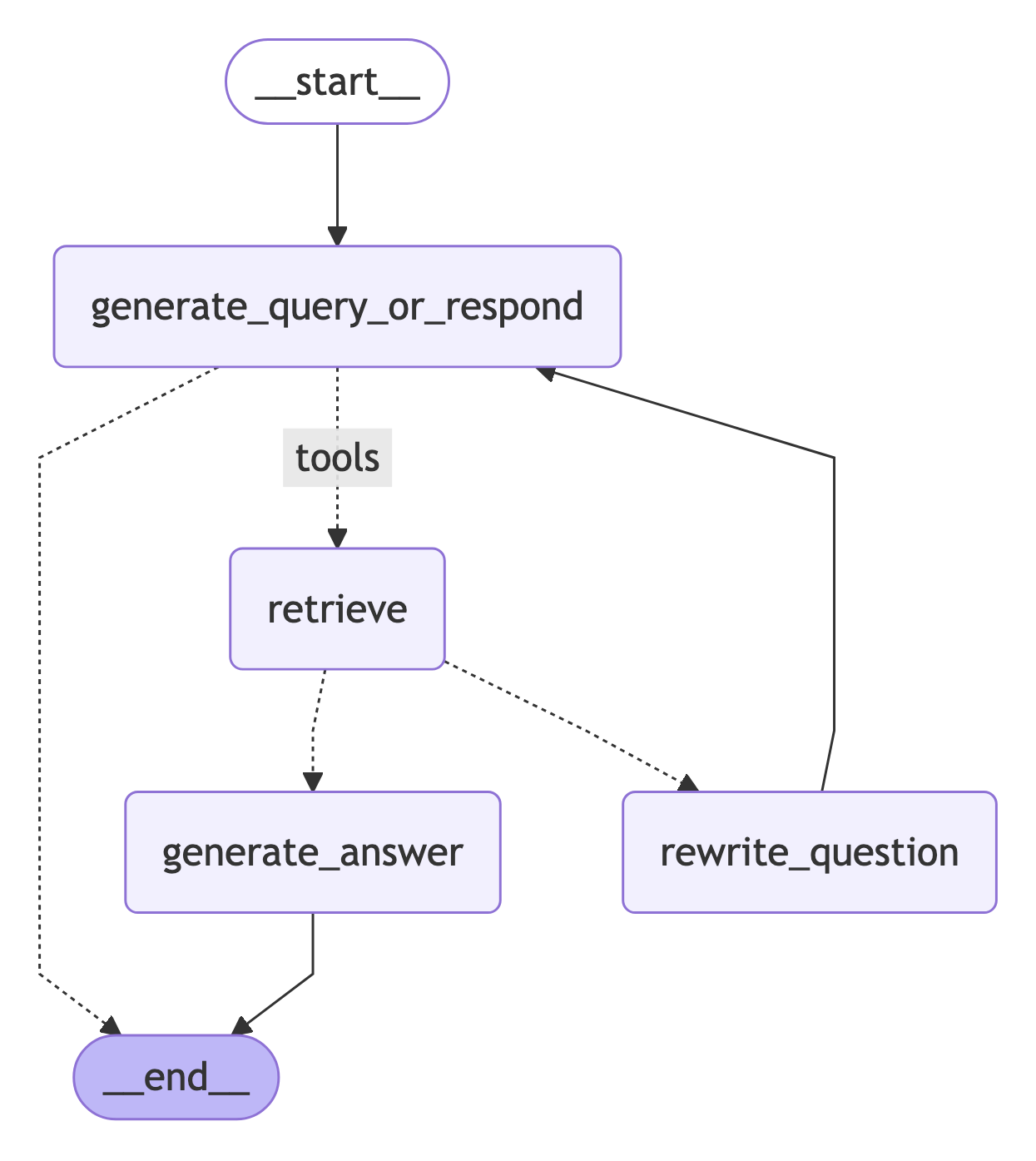
7. Assemble the graph
现在我们将所有节点和边组装成一个完整的图:- 从
generate_query_or_respond开始,确定是否需要调用retriever_tool - 使用
tools_condition路由到下一步:- 如果
generate_query_or_respond返回了tool_calls,调用retriever_tool检索上下文 - 否则,直接响应用户
- 如果
- 评估检索到的文档内容与问题的相关性(
grade_documents)并路由到下一步:- 如果不相关,使用
rewrite_question重写问题,然后再次调用generate_query_or_respond - 如果相关,继续到
generate_answer并使用带有检索到的文档上下文的ToolMessage生成最终响应
- 如果不相关,使用
8. Run the agentic RAG
现在让我们通过运行一个完整的问题来测试完整的图:Connect these docs to Claude, VSCode, and more via MCP for real-time answers.