

概念
我们将涵盖以下概念:设置
安装
LangSmith
Set up LangSmith to inspect what is happening inside your chain or agent. Then set the following environment variables:1. 选择 LLM
Select a model that supports tool-calling:- OpenAI
- Anthropic
- Azure
- Google Gemini
- AWS Bedrock
- HuggingFace
- OpenRouter
2. 配置数据库
You will be creating a SQLite database for this tutorial. SQLite is a lightweight database that is easy to set up and use. We will be loading thechinook database, which is a sample database that represents a digital media store.
For convenience, we have hosted the database (Chinook.db) on a public GCS bucket.
langchain_community package to interact with the database. The wrapper provides a simple interface to execute SQL queries and fetch results:
3. 添加数据库交互工具
Use theSQLDatabase wrapper available in the langchain_community package to interact with the database. The wrapper provides a simple interface to execute SQL queries and fetch results:
4. 定义应用程序步骤
We construct dedicated nodes for the following steps:- Listing DB tables
- Calling the “get schema” tool
- Generating a query
- Checking the query
5. Implement the agent
We can now assemble these steps into a workflow using the Graph API. We define a conditional edge at the query generation step that will route to the query checker if a query is generated, or end if there are no tool calls present, such that the LLM has delivered a response to the query.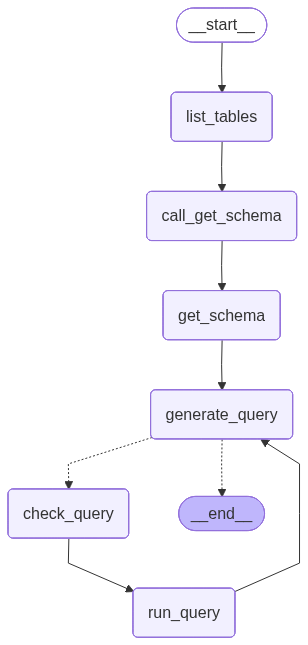 We can now invoke the graph:
We can now invoke the graph:
6. Implement human-in-the-loop review
It can be prudent to check the agent’s SQL queries before they are executed for any unintended actions or inefficiencies. Here we leverage LangGraph’s human-in-the-loop features to pause the run before executing a SQL query and wait for human review. Using LangGraph’s persistence layer, we can pause the run indefinitely (or at least as long as the persistence layer is alive). Let’s wrap thesql_db_query tool in a node that receives human input. We can implement this using the interrupt function. Below, we allow for input to approve the tool call, edit its arguments, or provide user feedback.
The above implementation follows the tool interrupt example in the broader human-in-the-loop guide. Refer to that guide for details and alternatives.
Next steps
Check out the Evaluate a graph guide for evaluating LangGraph applications, including SQL agents like this one, using LangSmith.Connect these docs to Claude, VSCode, and more via MCP for real-time answers.