

概述
构建代理(或任何 LLM 应用程序)的难点在于使它们足够可靠。虽然它们在原型中可能有效,但在实际使用场景中往往会失败。为什么代理会失败?
当代理失败时,通常是因为代理内部的 LLM 调用采取了错误的操作/没有按照我们的预期执行。LLM 失败的原因通常有两种:- 底层 LLM 能力不足
- 没有将”正确的”上下文传递给 LLM
代理循环
典型的代理循环由两个主要步骤组成:- 模型调用 - 使用提示和可用工具调用 LLM,返回响应或执行工具的请求
- 工具执行 - 执行 LLM 请求的工具,返回工具结果
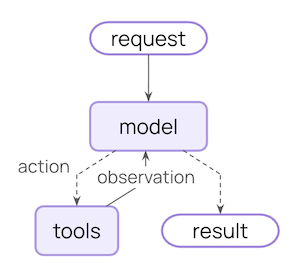
您可以控制的内容
要构建可靠的代理,您需要控制代理循环中每个步骤发生的事情,以及步骤之间发生的事情。临时上下文
LLM 在单次调用中看到的内容。您可以修改消息、工具或提示,而无需更改状态中保存的内容。
持久上下文
跨回合保存在状态中的内容。生命周期钩子和工具写入会永久修改此内容。
数据源
在此过程中,您的代理访问(读/写)不同的数据源:| 数据源 | 也称为 | 范围 | 示例 |
|---|---|---|---|
| 运行时上下文 | 静态配置 | 对话范围 | 用户 ID、API 密钥、数据库连接、权限、环境设置 |
| 状态 | 短期记忆 | 对话范围 | 当前消息、上传文件、认证状态、工具结果 |
| 存储 | 长期记忆 | 跨对话 | 用户偏好、提取的见解、记忆、历史数据 |
工作原理
LangChain 中间件 是使上下文工程对使用 LangChain 的开发者变得实用的底层机制。 中间件允许您钩入代理生命周期中的任何步骤并:- 更新上下文
- 跳转到代理生命周期中的不同步骤
模型上下文
控制每次模型调用的内容——指令、可用工具、使用哪个模型以及输出格式。这些决策直接影响可靠性和成本。系统提示词
开发者给 LLM 的基本指令。
消息
发送给 LLM 的完整消息列表(对话历史)。
工具
代理可用于执行操作的工具。
模型
要调用的实际模型(包括配置)。
响应格式
模型最终响应的模式规范。
系统提示词
系统提示词设置 LLM 的行为和能力。不同的用户、上下文或对话阶段需要不同的指令。成功的代理利用记忆、偏好和配置,为对话的当前状态提供正确的指令。- 状态
- 存储
- 运行时上下文
Access message count or conversation context from state:
消息
消息构成了发送给 LLM 的提示词。 管理消息的内容至关重要,以确保 LLM 有正确的信息来良好地响应。- 状态
- 存储
- 运行时上下文
在与当前查询相关时从状态注入上传文件的上下文:
Transient vs Persistent Message Updates:上面的示例使用
wrap_model_call 进行临时更新——修改发送给模型进行单次调用的消息,而不更改状态中保存的内容。要进行持久更新以修改状态,您可以:- Return a
ExtendedModelResponsewith aCommandfromwrap_model_callto inject state updates from the model call layer. - Use life-cycle hooks like
before_model,after_model, orwrap_tool_call(for tool returns) to update the conversation history. See the middleware documentation for more details.
Tools
工具允许模型与数据库、API 和外部系统交互。您如何定义和选择工具直接影响模型是否能有效地完成任务。Defining tools
每个工具都需要清晰的名称、描述、参数名和参数描述。这些不仅仅是元数据——它们指导模型何时以及如何使用该工具的推理。Selecting tools
并非每个工具都适用于每种情况。过多的工具可能会使模型不堪重负(上下文过载)并增加错误;过少的工具则限制了能力。动态工具选择根据认证状态、用户权限、功能标志或对话阶段来调整可用的工具集。- 状态
- 存储
- 运行时上下文
Enable advanced tools only after certain conversation milestones:
模型
不同的模型具有不同的优势、成本和上下文窗口。为手头的任务选择合适的模型,这在代理运行过程中可能会发生变化。- 状态
- 存储
- 运行时上下文
根据状态中的对话长度使用不同的模型:
响应格式
结构化输出将非结构化文本转换为经过验证的结构化数据。当提取特定字段或为下游系统返回数据时,自由格式的文本是不够的。 How it works: When you provide a schema as the response format, the model’s final response is guaranteed to conform to that schema. The agent runs the model / tool calling loop until the model is done calling tools, then the final response is coerced into the provided format.Defining formats
模式定义指导模型。字段名、类型和描述精确指定了输出应遵循的格式。Selecting formats
动态响应格式选择根据用户偏好、对话阶段或角色来调整模式——在早期返回简单格式,随着复杂性的增加返回详细格式。- 状态
- 存储
- 运行时上下文
Configure structured output based on conversation state:
工具上下文
工具的特殊之处在于它们既读取又写入上下文。 在最基本的情况下,当工具执行时,它接收 LLM 的请求参数并返回工具消息。工具完成其工作并产生结果。 工具还可以为模型获取重要信息,使其能够执行和完成任务。读取
大多数现实世界的工具需要的不仅仅是 LLM 的参数。它们需要用于数据库查询的用户 ID、用于外部服务的 API 密钥,或当前的会话状态来做出决策。工具从状态、存储和运行时上下文中读取以访问这些信息。- 状态
- 存储
- 运行时上下文
Read from State to check current session information:
写入
工具结果可用于帮助代理完成给定任务。工具既可以直接向模型返回结果,也可以更新代理的记忆,使重要的上下文在后续步骤中可用。- 状态
- 存储
使用 Command 写入状态以跟踪特定于会话的信息:
生命周期上下文
控制核心代理步骤之间发生的事情——拦截数据流以实现摘要、护栏和日志记录等横切关注点。 正如您在模型上下文和工具上下文中所见,中间件是使上下文工程变得实用的机制。中间件允许您钩入代理生命周期中的任何步骤,并且可以:- Update context - Modify state and store to persist changes, update conversation history, or save insights
- Jump in the lifecycle - Move to different steps in the agent cycle based on context (e.g., skip tool execution if a condition is met, repeat model call with modified context)
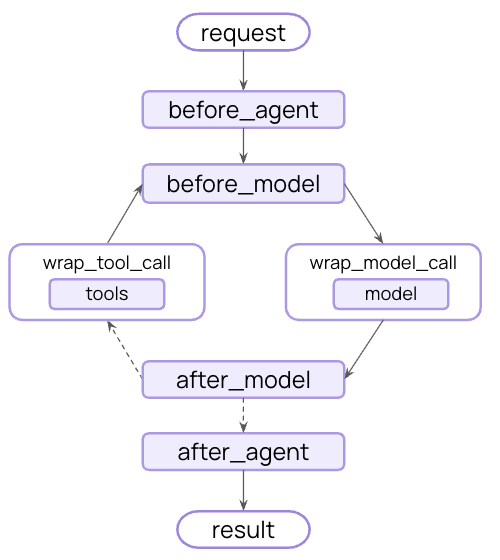
Example: Summarization
最常见的生命周期模式之一是在对话历史变得过长时自动压缩它。与模型上下文中显示的临时消息修剪不同,摘要持久更新状态——永久地用摘要替换旧消息,该摘要将保存用于所有后续回合。 LangChain 为此提供了内置中间件:SummarizationMiddleware 会自动:
- 使用单独的 LLM 调用摘要较早的消息
- 在状态中用摘要消息替换它们(永久性)
- 保持最近的消息完整以提供上下文
有关内置中间件的完整列表、可用的钩子以及如何创建自定义中间件,请参阅中间件文档。
最佳实践
- 从简单开始 - 从静态提示和工具开始,仅在需要时添加动态功能
- 增量测试 - 一次添加一个上下文工程功能
- 监控性能 - 跟踪模型调用、token 使用量和延迟
- 使用内置中间件 - 利用
SummarizationMiddleware、LLMToolSelectorMiddleware等 - 记录您的上下文策略 - 明确传递了什么上下文以及为什么传递
- 理解临时与持久:模型上下文更改是临时的(每次调用),而生命周期上下文更改会持久保存到状态
相关资源
通过 MCP 连接这些文档 到 Claude、VSCode 等,获取实时答案。